Block Components
Abstract
The block package provides a modular component-based architecture for handling block-related operations in full nodes. Instead of a single monolithic manager, the system is divided into specialized components that work together, each responsible for specific aspects of block processing. This architecture enables better separation of concerns, easier testing, and more flexible node configurations.
The main components are:
- Executor: Handles block production and state transitions (aggregator nodes only)
- Reaper: Periodically retrieves transactions and submits them to the sequencer (aggregator nodes only)
- Submitter: Manages submission of headers and data to the DA network (aggregator nodes only)
- Syncer: Handles synchronization from both DA and P2P sources (all full nodes)
- Cache Manager: Coordinates caching and tracking of blocks across all components
A full node coordinates these components based on its role:
- Aggregator nodes: Use all components for block production, submission, and synchronization
- Non-aggregator full nodes: Use only Syncer and Cache for block synchronization
Component Architecture Overview
Protocol/Component Description
The block components are initialized based on the node type:
Aggregator Components
Aggregator nodes create all components for full block production and synchronization capabilities:
components := block.NewAggregatorComponents(
config, // Node configuration
genesis, // Genesis state
store, // Local datastore
executor, // Core executor for state transitions
sequencer, // Sequencer client
da, // DA client
signer, // Block signing key
// P2P stores and options...
)Non-Aggregator Components
Non-aggregator full nodes create only synchronization components:
components := block.NewSyncComponents(
config, // Node configuration
genesis, // Genesis state
store, // Local datastore
executor, // Core executor for state transitions
da, // DA client
// P2P stores and options... (no signer or sequencer needed)
)Component Initialization Parameters
| Name | Type | Description |
|---|---|---|
| signing key | crypto.PrivKey | used for signing blocks and data after creation |
| config | config.BlockManagerConfig | block manager configurations (see config options below) |
| genesis | *cmtypes.GenesisDoc | initialize the block manager with genesis state (genesis configuration defined in config/genesis.json file under the app directory) |
| store | store.Store | local datastore for storing chain blocks and states (default local store path is $db_dir/evolve and db_dir specified in the config.yaml file under the app directory) |
| mempool, proxyapp, eventbus | mempool.Mempool, proxy.AppConnConsensus, *cmtypes.EventBus | for initializing the executor (state transition function). mempool is also used in the manager to check for availability of transactions for lazy block production |
| dalc | da.DAClient | the data availability light client used to submit and retrieve blocks to DA network |
| headerStore | *goheaderstore.Store[*types.SignedHeader] | to store and retrieve block headers gossiped over the P2P network |
| dataStore | *goheaderstore.Store[*types.SignedData] | to store and retrieve block data gossiped over the P2P network |
| signaturePayloadProvider | types.SignaturePayloadProvider | optional custom provider for header signature payloads |
| sequencer | core.Sequencer | used to retrieve batches of transactions from the sequencing layer |
| reaper | *Reaper | component that periodically retrieves transactions from the executor and submits them to the sequencer |
Configuration Options
The block components share a common configuration:
| Name | Type | Description |
|---|---|---|
| BlockTime | time.Duration | time interval used for block production and block retrieval from block store (defaultBlockTime) |
| DABlockTime | time.Duration | time interval used for both block publication to DA network and block retrieval from DA network (defaultDABlockTime) |
| DAStartHeight | uint64 | block retrieval from DA network starts from this height |
| LazyBlockInterval | time.Duration | time interval used for block production in lazy aggregator mode even when there are no transactions (defaultLazyBlockTime) |
| LazyMode | bool | when set to true, enables lazy aggregation mode which produces blocks only when transactions are available or at LazyBlockInterval intervals |
| MaxPendingHeadersAndData | uint64 | maximum number of pending headers and data blocks before pausing block production (default: 100) |
| MaxSubmitAttempts | int | maximum number of retry attempts for DA submissions (default: 30) |
| MempoolTTL | int | number of blocks to wait when transaction is stuck in DA mempool (default: 25) |
| GasPrice | float64 | gas price for DA submissions (-1 for automatic/default) |
| GasMultiplier | float64 | multiplier for gas price on DA submission retries (default: 1.3) |
| Namespace | da.Namespace | DA namespace ID for block submissions (deprecated, use HeaderNamespace and DataNamespace instead) |
| HeaderNamespace | string | namespace ID for submitting headers to DA layer (automatically encoded by the node) |
| DataNamespace | string | namespace ID for submitting data to DA layer (automatically encoded by the node) |
| RequestTimeout | duration | per-request timeout for DA GetIDs/Get calls; higher values tolerate slow DA nodes, lower values fail faster (default: 30s) |
Block Production (Executor Component)
When the full node is operating as an aggregator, the Executor component handles block production. There are two modes of block production, which can be specified in the block manager configurations: normal and lazy.
In normal mode, the block manager runs a timer, which is set to the BlockTime configuration parameter, and continuously produces blocks at BlockTime intervals.
In lazy mode, the block manager implements a dual timer mechanism:
- A
blockTimerthat triggers block production at regular intervals when transactions are available - A
lazyTimerthat ensures blocks are produced atLazyBlockIntervalintervals even during periods of inactivity
The block manager starts building a block when any transaction becomes available in the mempool via a notification channel (txNotifyCh). When the Reaper detects new transactions, it calls Manager.NotifyNewTransactions(), which performs a non-blocking signal on this channel. The block manager also produces empty blocks at regular intervals to maintain consistency with the DA layer, ensuring a 1:1 mapping between DA layer blocks and execution layer blocks.
The Reaper component periodically retrieves transactions from the core executor and submits them to the sequencer. It runs independently and notifies the Executor component when new transactions are available, enabling responsive block production in lazy mode.
Building the Block
The Executor component of aggregator nodes performs the following steps to produce a block:
- Retrieve a batch of transactions using
retrieveBatch()which interfaces with the sequencer - Call
CreateBlockusing executor with the retrieved transactions - Create separate header and data structures from the block
- Sign the header using
signing keyto generateSignedHeader - Sign the data using
signing keyto generateSignedData(if transactions exist) - Call
ApplyBlockusing executor to generate an updated state - Save the block, validators, and updated state to local store
- Add the newly generated header to
pendingHeadersqueue - Add the newly generated data to
pendingDataqueue (if not empty) - Publish the newly generated header and data to channels to notify other components of the sequencer node (such as block and header gossip)
Note: When no transactions are available, the block manager creates blocks with empty data using a special dataHashForEmptyTxs marker. The header and data separation architecture allows headers and data to be submitted and retrieved independently from the DA layer.
Block Publication to DA Network (Submitter Component)
The Submitter component of aggregator nodes implements separate submission loops for headers and data, both operating at DABlockTime intervals. Headers and data are submitted to different namespaces to improve scalability and allow for more flexible data availability strategies:
Header Submission Loop
The HeaderSubmissionLoop manages the submission of signed headers to the DA network:
- Retrieves pending headers from the
pendingHeadersqueue - Marshals headers to protobuf format
- Submits to DA using the generic
submitToDAhelper with the configuredHeaderNamespace - On success, removes submitted headers from the pending queue
- On failure, headers remain in the queue for retry
Data Submission Loop
The DataSubmissionLoop manages the submission of signed data to the DA network:
- Retrieves pending data from the
pendingDataqueue - Marshals data to protobuf format
- Submits to DA using the generic
submitToDAhelper with the configuredDataNamespace - On success, removes submitted data from the pending queue
- On failure, data remains in the queue for retry
Generic Submission Logic
Both loops use a shared submitToDA function that provides:
- Namespace-specific submission based on header or data type
- Retry logic with configurable maximum attempts via
MaxSubmitAttemptsconfiguration - Exponential backoff starting at
initialBackoff(100ms), doubling each attempt, capped atDABlockTime - Gas price management with
GasMultiplierapplied on retries using a centralizedretryStrategy - Recursive batch splitting for handling "too big" DA submissions that exceed blob size limits
- Comprehensive error handling for different DA submission failure types (mempool issues, context cancellation, blob size limits)
- Comprehensive metrics tracking for attempts, successes, and failures
- Context-aware cancellation support
Retry Strategy and Error Handling
The DA submission system implements sophisticated retry logic using a centralized retryStrategy struct to handle various failure scenarios:
Retry Strategy Features
- Centralized State Management: The
retryStrategystruct manages attempt counts, backoff timing, and gas price adjustments - Multiple Backoff Types:
- Exponential backoff for general failures (doubles each attempt, capped at
BlockTime) - Mempool-specific backoff (waits
MempoolTTL * BlockTimefor stuck transactions) - Success-based backoff reset with gas price reduction
- Exponential backoff for general failures (doubles each attempt, capped at
- Gas Price Management:
- Increases gas price by
GasMultiplieron mempool failures - Decreases gas price after successful submissions (bounded by initial price)
- Supports automatic gas price detection (
-1value)
- Increases gas price by
- Intelligent Batch Splitting:
- Recursively splits batches that exceed DA blob size limits
- Handles partial submissions within split batches
- Prevents infinite recursion with proper base cases
- Comprehensive Error Classification:
StatusSuccess: Full or partial successful submissionStatusTooBig: Triggers batch splitting logicStatusNotIncludedInBlock/StatusAlreadyInMempool: Mempool-specific handlingStatusContextCanceled: Graceful shutdown support- Other errors: Standard exponential backoff
The manager enforces a limit on pending headers and data through MaxPendingHeadersAndData configuration. When this limit is reached, block production pauses to prevent unbounded growth of the pending queues.
Block Retrieval from DA Network (Syncer Component)
The Syncer component implements a RetrieveLoop through its DARetriever that regularly pulls headers and data from the DA network. The retrieval process supports both legacy single-namespace mode (for backward compatibility) and the new separate namespace mode:
Retrieval Process
Height Management: Starts from the latest of:
- DA height from the last state in local store
DAStartHeightconfiguration parameter- Maintains and increments
daHeightcounter after successful retrievals
Retrieval Mechanism:
- Executes at
DABlockTimeintervals - Implements namespace migration support:
- First attempts legacy namespace retrieval if migration not completed
- Falls back to separate header and data namespace retrieval
- Tracks migration status to optimize future retrievals
- Retrieves from separate namespaces:
- Headers from
HeaderNamespace - Data from
DataNamespace
- Headers from
- Combines results from both namespaces
- Handles three possible outcomes:
Success: Process retrieved header and/or dataNotFound: No chain block at this DA height (normal case)Error: Retry with backoff
- Executes at
Error Handling:
- Implements retry logic with 100ms delay between attempts
- After 10 retries, logs error and stalls retrieval
- Does not increment
daHeighton persistent errors
Processing Retrieved Blocks:
- Validates header and data signatures
- Checks sequencer information
- Marks blocks as DA included in caches
- Sends to sync goroutine for state update
- Successful processing triggers immediate next retrieval without waiting for timer
- Updates namespace migration status when appropriate:
- Marks migration complete when data is found in new namespaces
- Persists migration state to avoid future legacy checks
Header and Data Caching
The retrieval system uses persistent caches for both headers and data:
- Prevents duplicate processing
- Tracks DA inclusion status
- Supports out-of-order block arrival
- Enables efficient sync from P2P and DA sources
- Maintains namespace migration state for optimized retrieval
For more details on DA integration, see the Data Availability specification.
Out-of-Order Chain Blocks on DA
Evolve should support blocks arriving out-of-order on DA, like so: 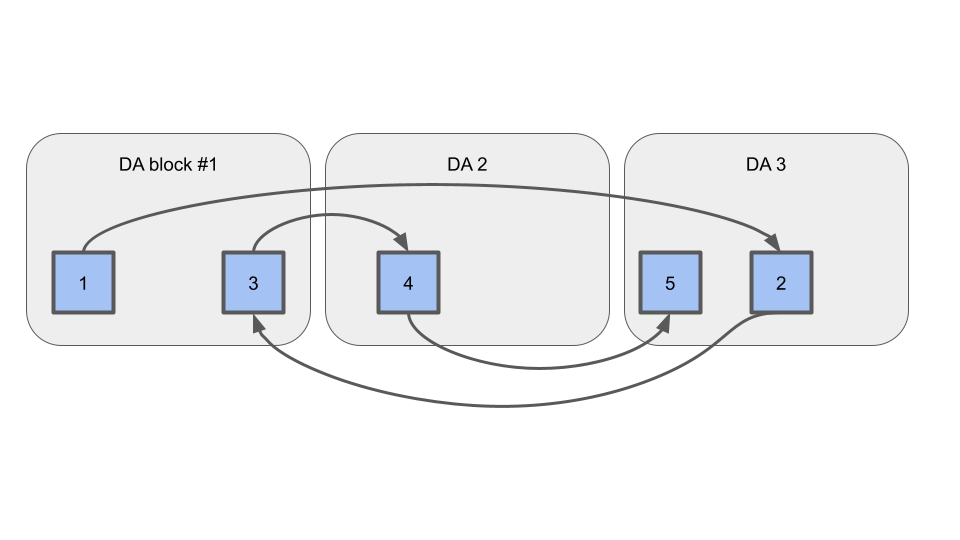
Termination Condition
If the sequencer double-signs two blocks at the same height, evidence of the fault should be posted to DA. Evolve full nodes should process the longest valid chain up to the height of the fault evidence, and terminate. See diagram: 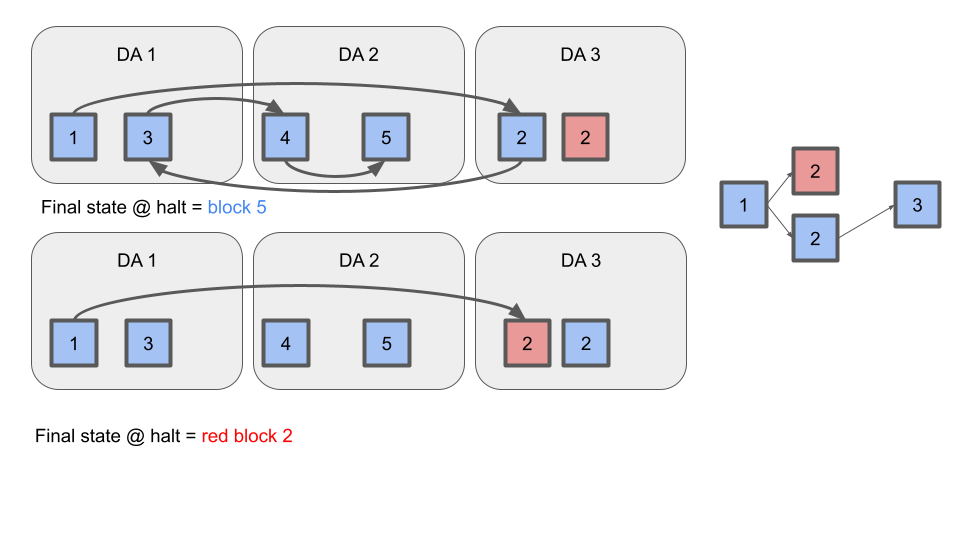
Block Sync Service (Syncer Component)
The Syncer component manages the synchronization of headers and data through its P2PHandler and coordination with the Cache Manager:
Architecture
- Header Store: Uses
goheader.Store[*types.SignedHeader]for header management - Data Store: Uses
goheader.Store[*types.SignedData]for data management - Separation of Concerns: Headers and data are handled independently, supporting the header/data separation architecture
Synchronization Flow
- Header Sync: Headers created by the sequencer are sent to the header store for P2P gossip
- Data Sync: Data blocks are sent to the data store for P2P gossip
- Cache Integration: Both header and data caches track seen items to prevent duplicates
- DA Inclusion Tracking: Separate tracking for header and data DA inclusion status
Block Publication to P2P network (Executor Component)
The Executor component of aggregator nodes publishes headers and data separately to the P2P network:
Header Publication
- Headers are sent through the header broadcast channel
- Written to the header store for P2P gossip
- Broadcast to network peers via header sync service
Data Publication
- Data blocks are sent through the data broadcast channel
- Written to the data store for P2P gossip
- Broadcast to network peers via data sync service
Non-sequencer full nodes receive headers and data through the P2P sync service and do not publish blocks themselves.
Block Retrieval from P2P network (Syncer Component)
The Syncer component retrieves headers and data separately from P2P stores through its P2PHandler:
Header Store Retrieval Loop
The HeaderStoreRetrieveLoop:
- Operates at
BlockTimeintervals viaheaderStoreChsignals - Tracks
headerStoreHeightfor the last retrieved header - Retrieves all headers between last height and current store height
- Validates sequencer information using
assertUsingExpectedSingleSequencer - Marks headers as "seen" in the header cache
- Sends headers to sync goroutine via
headerInCh
Data Store Retrieval Loop
The DataStoreRetrieveLoop:
- Operates at
BlockTimeintervals viadataStoreChsignals - Tracks
dataStoreHeightfor the last retrieved data - Retrieves all data blocks between last height and current store height
- Validates data signatures using
assertValidSignedData - Marks data as "seen" in the data cache
- Sends data to sync goroutine via
dataInCh
Soft Confirmations
Headers and data retrieved from P2P are marked as soft confirmed until both:
- The corresponding header is seen on the DA layer
- The corresponding data is seen on the DA layer
Once both conditions are met, the block is marked as DA-included.
About Soft Confirmations and DA Inclusions
The block manager retrieves blocks from both the P2P network and the underlying DA network because the blocks are available in the P2P network faster and DA retrieval is slower (e.g., 1 second vs 6 seconds). The blocks retrieved from the P2P network are only marked as soft confirmed until the DA retrieval succeeds on those blocks and they are marked DA-included. DA-included blocks are considered to have a higher level of finality.
DAIncluderLoop: The DAIncluderLoop is responsible for advancing the DAIncludedHeight by:
- Checking if blocks after the current height have both header and data marked as DA-included in caches
- Stopping advancement if either header or data is missing for a height
- Calling
SetFinalon the executor when a block becomes DA-included - Storing the Evolve height to DA height mapping for tracking
- Ensuring only blocks with both header and data present are considered DA-included
State Update after Block Retrieval (Syncer Component)
The Syncer component uses a SyncLoop to coordinate state updates from blocks retrieved via P2P or DA networks:
Sync Loop Architecture
The SyncLoop processes headers and data from multiple sources:
- Headers from
headerInCh(P2P and DA sources) - Data from
dataInCh(P2P and DA sources) - Maintains caches to track processed items
- Ensures ordered processing by height
State Update Process
When both header and data are available for a height:
- Block Reconstruction: Combines header and data into a complete block
- Validation: Verifies header and data signatures match expectations
- ApplyBlock:
- Validates the block against current state
- Executes transactions
- Captures validator updates
- Returns updated state
- Commit:
- Persists execution results
- Updates mempool by removing included transactions
- Publishes block events
- Storage:
- Stores the block, validators, and updated state
- Updates last state in manager
- Finalization:
- When block is DA-included, calls
SetFinalon executor - Updates DA included height
- When block is DA-included, calls
Message Structure/Communication Format
Component Communication
The components communicate through well-defined interfaces:
Executor ↔ Core Executor
InitChain: initializes the chain state with the given genesis time, initial height, and chain ID usingInitChainSyncon the executor to obtain initialappHashand initialize the state.CreateBlock: prepares a block with transactions from the provided batch data.ApplyBlock: validates the block, executes the block (apply transactions), captures validator updates, and returns updated state.SetFinal: marks the block as final when both its header and data are confirmed on the DA layer.GetTxs: retrieves transactions from the application (used by Reaper component).
Reaper ↔ Sequencer
GetNextBatch: retrieves the next batch of transactions to include in a block.VerifyBatch: validates that a batch came from the expected sequencer.
Submitter/Syncer ↔ DA Layer
Submit: submits headers or data blobs to the DA network.Get: retrieves headers or data blobs from the DA network.GetHeightPair: retrieves both header and data at a specific DA height.
Assumptions and Considerations
Component Architecture
- The block package uses a modular component architecture instead of a monolithic manager
- Components are created based on node type: aggregator nodes get all components, non-aggregator nodes only get synchronization components
- Each component has a specific responsibility and communicates through well-defined interfaces
- Components share a common Cache Manager for coordination and state tracking
Initialization and State Management
- Components load the initial state from the local store and use genesis if not found in the local store, when the node (re)starts
- During startup the Syncer invokes the execution Replayer to re-execute any blocks the local execution layer is missing; the replayer enforces strict app-hash matching so a mismatch aborts initialization instead of silently drifting out of sync
- The default mode for aggregator nodes is normal (not lazy)
- Components coordinate through channels and shared cache structures
Block Production (Executor Component)
- The Executor can produce empty blocks
- In lazy aggregation mode, the Executor maintains consistency with the DA layer by producing empty blocks at regular intervals, ensuring a 1:1 mapping between DA layer blocks and execution layer blocks
- The lazy aggregation mechanism uses a dual timer approach:
- A
blockTimerthat triggers block production when transactions are available - A
lazyTimerthat ensures blocks are produced even during periods of inactivity
- A
- Empty batches are handled differently in lazy mode - instead of discarding them, they are returned with the
ErrNoBatcherror, allowing the caller to create empty blocks with proper timestamps - Transaction notifications from the
Reaperto theExecutorare handled via a non-blocking notification channel (txNotifyCh) to prevent backpressure
DA Submission (Submitter Component)
- The Submitter enforces
MaxPendingHeadersAndDatalimit to prevent unbounded growth of pending queues during DA submission issues - Headers and data are submitted separately to the DA layer using different namespaces, supporting the header/data separation architecture
- The Cache Manager uses persistent caches for headers and data to track seen items and DA inclusion status
- Namespace migration is handled transparently by the Syncer, with automatic detection and state persistence to optimize future operations
- The system supports backward compatibility with legacy single-namespace deployments while transitioning to separate namespaces
- Gas price management in the Submitter includes automatic adjustment with
GasMultiplieron DA submission retries
Storage and Persistence
- Components use persistent storage (disk) when the
root_diranddb_pathconfiguration parameters are specified inconfig.yamlfile under the app directory. If these configuration parameters are not specified, the in-memory storage is used, which will not be persistent if the node stops - The Syncer does not re-apply blocks when they transition from soft confirmed to DA included status. The block is only marked DA included in the caches
- Header and data stores use separate prefixes for isolation in the underlying database
- The genesis
ChainIDis used to create separatePubSubTopIDs for headers and data in go-header
P2P and Synchronization
- Block sync over the P2P network works only when a full node is connected to the P2P network by specifying the initial seeds to connect to via
P2PConfig.Seedsconfiguration parameter when starting the full node - Node's context is passed down to all components to support graceful shutdown and cancellation
Architecture Design Decisions
- The Executor supports custom signature payload providers for headers, enabling flexible signing schemes
- The component architecture supports the separation of header and data structures in Evolve. This allows for expanding the sequencing scheme beyond single sequencing and enables the use of a decentralized sequencer mode. For detailed information on this architecture, see the Header and Data Separation ADR
- Components process blocks with a minimal header format, which is designed to eliminate dependency on CometBFT's header format and can be used to produce an execution layer tailored header if needed. For details on this header structure, see the Evolve Minimal Header specification
Metrics
The block components expose comprehensive metrics for monitoring through the shared Metrics instance:
Block Production Metrics (Executor Component)
last_block_produced_height: Height of the last produced blocklast_block_produced_time: Timestamp of the last produced blockaggregation_type: Current aggregation mode (normal/lazy)block_size_bytes: Size distribution of produced blocksproduced_empty_blocks_total: Count of empty blocks produced
DA Metrics (Submitter and Syncer Components)
da_submitter_pending_blobs: Total of Header/Data pending blobsda_submission_attempts_total: Total DA submission attemptsda_submission_success_total: Successful DA submissionsda_submission_failure_total: Failed DA submissionsda_retrieval_attempts_total: Total DA retrieval attemptsda_retrieval_success_total: Successful DA retrievalsda_retrieval_failure_total: Failed DA retrievalsda_height: Current DA retrieval height
Sync Metrics (Syncer Component)
sync_height: Current sync heightda_included_height: Height of last DA-included blocksoft_confirmed_height: Height of last soft confirmed blockheader_store_height: Current header store heightdata_store_height: Current data store height
Performance Metrics (All Components)
block_production_time: Time to produce a blockda_submission_time: Time to submit to DAstate_update_time: Time to apply block and update statechannel_buffer_usage: Usage of internal channels
Error Metrics (All Components)
errors_total: Total errors by type and operation
Implementation
The modular block components are implemented in the following packages:
- Executor: Block production and state transitions (
block/internal/executing/) - Reaper: Transaction collection and submission (
block/internal/reaping/) - Submitter: DA submission logic (
block/internal/submitting/) - Syncer: Block synchronization from DA and P2P (
block/internal/syncing/) - Cache Manager: Coordination and state tracking (
block/internal/cache/) - Components: Main components orchestration (
block/components.go)
See tutorial for running a multi-node network with both aggregator and non-aggregator full nodes.
References
[1] Go Header
[2] Block Sync
[3] Full Node
[4] Block Components
[5] Tutorial